著名的计算机专家David Wheeler曾说过,“在计算机领域所有的问题,没有任何一个问题不能通过添加一层抽象来解决。”
Alluxio创立于2015年,是全球首创开源云原生数据编排软件开发商,为解决数据本地、数据抽象以及可访问等技术难题,Alluxio在计算和存储的中间插入了一个数据编排层。该数据编排层就是Alluxio带给计算机领域的一层抽象。
Alluxio的创始人兼CEO李浩源本科毕业于北京大学计算机系,曾代表北京大学获得大学生国际编程比赛(ACM ICPC)全球第11名。在康奈尔大学获取硕士学位后,又继续在加州大学伯克利分校AMPLab攻读博士,博士期间,师从分布式系统和网络领域的泰斗Ion Stoica教授和Scott Shenker教授。在SOSP/NSDI等国际顶级会议发表论文10余篇,Google Scholar 引用量达3000 。
博士期间,李浩源在AMP实验室里孵化了Alluxio(曾用名Tachyon)的技术原型,并获得了硅谷和中国著名风投机构的投资,而后正式成立Alluxio公司并致力于该技术的商业化。
今年,依据Google在Github上发布的评选结果,Alluxio领导的开源社区项目被评为全球最重要的Java开源项目前十名。
公司的核心产品Alluxio系统,是全球首个分布式超大规模数据编排系统。自项目开源以来,已有超过来自300多个组织机构的1100多位贡献者参与开发。Alluxio能够在跨集群、跨区域、跨国家的任何云中将数据更紧密地编排,以接近数据分析和AI/ML应用程序,从而向上层应用提供了内存级别的数据访问速度。
如今,人们已经身处信息爆炸时代,用大数据来引发一场新的革命不再是一次对几年后的预言。越来越多的企业数据量已经达到上亿级,数据源爆炸式增长、数据云上迁移,以及大数据技术栈和厂商呈碎片化趋势等问题,对数据平台的架构提出了敏捷性、成本效益、性能等各种要求。
面对如此庞大的数据,企业如何更稳定、快速地调取出来进行计算和机器学习,成了很多技术人员要去解决的问题。
SQL是一种访问、处理数据库的计算机语言,MySQL、oracle这些都是SQL数据库,能够快速查询和处理数据,但它们的不足之处是只能查询和处理一些小规模数据,碰到以亿为单位的海量数据时,性能和速度就会明显下降。这种限制使得它们难以满足当下超大型企业的需求。
而它们难以做到的,Presto可以做到。Presto是一款Facebook开源的MPP架构的OLAP查询引擎,也是一款可以针对不同数据源执行大容量数据集的分布式SQL执行引擎。
不同于传统的数据库去管理数据存储,Presto是一款分布式SQL执行引擎,它将计算和存储分离,将存储交给了HDFS、GCS、S3等第三方平台,而自己只负责计算。如此,Presto就可以实现处理海量数据的功能。但也正是由于Presto不负责存储,导致了企业在调取数据时,需要从储存数据的源头去读取,在速度等方面表现较差。
举个例子,虽然大家都觉得互联网的速度非常快,但当你去国外旅行,跟家人视频通话时,就会发现视频的清晰度和流畅度远不如你和家人都在国内时。原因在于数据的传输距离,传输距离变长了,就会有更多的网关、路由器,延时就会增长。
Presto没有存储自己的数据,要查询任何数据,都需要将数据集读出来,将每行都扫描一遍,如此,读取速度就非常依赖于网络传输的速度。
现在很多新兴的互联网公司最常用的一种架构,就是将数据完全上云,放在云平台上,这样企业自己就不用建数据中心了。但从云上调取数据,一方面费用很高,另一方面调取速度很慢,更不用提如今有越来越多的将数据存放在硬盘上的企业了。
Alluxio对此的解决方法是,在计算和存储之间做一层缓存机制,将该缓存机制和Presto或其他的计算引擎部署到一起。由于这类计算引擎并不负责存储工作,该缓存机制作为中间层来负责存储工作,这个中间层就是Alluxio。
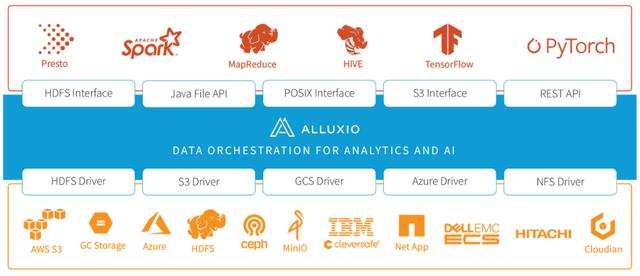
Alluxio的数据编排层
那么Alluxio具体是如何工作的呢?
其实,在第一次调取数据时,Alluxio的速度会和Presto等计算引擎调取数据的速度是一样的,真正的差别要从第二次开始计算。
因为Alluxio会在第一次调取数据后对数据进行缓存,当企业第二次调取同样的数据时,速度自然会成倍提高,加上如今企业的海量数据中,其实有很多数据都会被反复调取使用,缓存机制就大大提高了第二次调取后的效率。
简而言之即如果数据在Alluxio集群里边,从Alluxio中就可以拿到,不用去数据中心重新读取,如果该数据没在Alluxio集群里,就让Alluxio到云上将数据拿回来,并进行存储。
此外,由于各种存储方式的价格、不同地域对数据的管理政策不同,现在很多企业不会只局限于在一种云服务上,企业的数据就会分散在不同地区或者不同种类的数据存储服务中。从不同的存储服务中调取数据,难免会存在一个“翻译”的过程,Alluxio在该过程中起到了一个翻译官的作用,可以支持用户使用不同技术栈及访问接口,而无需关心究竟底层使用了何种数据存储服务,从而让数据流动更加透明和高效。
无论企业的数据平台位于本地、公有云、还是混合云的环境,无论使用什么样的技术栈,Alluxio都可以让任何的计算对存储实现高性能的访问。通过把Alluxio部署在数据平台里,企业可以灵活地测试和实施新技术,从而保持敏捷性和竞争力。
李浩源告诉创业邦,“我们行业的演进主要来自整个社会和各行业数字化进程的驱动。由于社会和行业都更加数字化,数据越来越多,基于数据的存储、数据分析、机器学习等各式各样的产品在增加,导致出现了一个分割的数据世界和复杂的数据平台,也就直接导致了数据调取的低效。”
Alluxio为数据驱动型应用和存储系统构建了桥梁,将数据从存储层移动到距离数据驱动型应用更近的位置,从而不仅能够更容易被访问,还可以达到内存级的访问速度。同时,Alluxio还实现了应用程序能够通过一个公共接口连接到许多存储系统。
11月18日,Alluxio宣布正式发布其数据编排平台2.7版本,2.7版本通过并行数据加载、数据预处理和训练工作流,可将机器学习 (ML) 训练的I/O效率提高8-12倍,从而降低企业调取数据的成本。2.7版本还提供了更强的性能分析功能,能更好地支持Apache Hudi和Iceberg等开放表格格式,使得对数据湖的访问更易于扩展,实现了Presto和Spark的数据分析能力的提速。
李浩源针对此次的2.7版本表示,“Alluxio 2.7版本进一步巩固了Alluxio在云上人工智能、机器学习和深度学习方面的重要地位。随着数据集的增长以及CPU和GPU计算能力的增强,机器学习和深度学习已成为AI主流技术。这些技术的兴起推动了AI的发展,但也凸显了数据和存储系统访问中存在的一些挑战。”
当前,Alluxio的合作伙伴超过九成都是世界五百强企业,其所开创的数据编排技术已经在不同垂直领域的国内外头部公司被广泛应用,其中不乏诸如Facebook、Amazon、腾讯、阿里巴巴、百度、联通在内的行业巨头。全球十大互联网公司中有八家已经在生产环境中部署了Alluxio。
腾讯大数据平台研发负责人陈鹏表示,“随着越来越多的大数据和AI应用容器化,作为加速数据分析和模型训练的中间层,Alluxio正在成为大型企业和机构的首选。”
从行业的角度来看,Alluxio的客户中,渗透率最高的是科技行业,排在第二的是金融行业,第三是电信行业,第四是基因制药行业。
李浩源表示,出现这样一个排序的原因在于当一个行业数字化进程越深,Alluxio的软件价值就越高,渗透率就会越高,自然而然使用的客户就会越多。
值得一提的是,今年,在中国信通院发布的第二批32家开源供应商名录中,Alluxio凭借Alluxio云端数据编排平台、Alluxio加速器和Alluxio虚拟数据湖,成功跻身云计算、中间件和大数据三大产品类型的开源供应商。
鉴于“开源开放”有助于推动我国数字化转型和数字经济发展,“开源开放”已被列入我国十四五规划和2035年远景目标。
在此背景下,今年,Alluxio 宣布将大力拓展国内市场业务,将北京设立为中国区总部,并成立本地化的研发团队,以快速响应并满足众多国内企业的个性化需求,以及推动扎根于中国的开源社区运营、治理和推广,与行业一同搭建可信开源生态链,在国内建设一个可持续发展的开源社区。Alluxio在其开源软件Alluxio的基础上进行封装,未来,要向企业级客户持续提供丰富的应用场景,并不断升级其软件服务。
图片来源:Alluxio、摄图网
从大数据入门,到达到一定水平,在学习路径上有什么建议
目前我们正处在大数据时代,掌握大数据相关技术对提高自己的职场竞争力一定是有帮助的。
大数据学习建议:
1、0基础小白从Java语言开始学习
因为当前的大数据技术主要是用 Java 实现的或者是基于 Java 的,想入行大数据,Java基础是必备的;
2、Java开发能力需要通过实际项目来锻炼
在学习完Java语言之后,往往只是掌握了Java语言的基本操作,只有通过真正的项目锻炼才能进一步提高Java开发能力。
3、大数据开发有明显的场景要求
大数据开发是基于目前已有信息系统的升级改造,是一个系统的过程,包括平台的搭建、数据的存储、服务的部署等都有较大的变化,要想真正理解大数据需要有一个积累的过程。对于初学者来说,应该先建立一个对开发场景的认知,这样会更好的理解大数据平台的价值和作用。
4、从基础开发开始做起
对于初级程序员来说,不管自己是否掌握大数据平台的开发知识,都是从基础的开发开始做起,基于大数据平台开发环境。
从就业的角度来说,大数据开发是一个不错的选择。但我并不建议脱离实际应用来学习大数据,最好要结合实际的开发任务来一边学习一边使用。
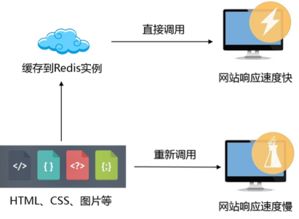
分布式缓存主要用在高并发环境下的作用?
分布式缓存主要用在高并发环境下,减轻数据库的压力,提高系统的响应速度和并发吞吐。当大量的读、写请求涌向数据库时,磁盘的处理速度与内存显然不在一个量级,因此,在数据库之前加一层缓存,能够显著提高系统的响应速度,并降低数据库的压力。作为传统的关系型数据库,MySQL提供完整的ACID操作,支持丰富的数据类型、强大的关联查询、where语句等,能够非常客易地建立查询索引,执行复杂的内连接、外连接、求和、排序、分组等操作,并且支持存储过程、函数等功能,产品成熟度高,功能强大。但是,对于需要应对高并发访问并且存储海量数据的场景来说,出于对性能的考虑,不得不放弃很多传统关系型数据库原本强大的功能,牺牲了系统的易用性,并且使得系统的设计和管理变得更为复杂。这也使得在过去几年中,流行着另一种新的存储解决方案——NoSQL,它与传统的关系型数据库最大的差别在于,它不使用SQL作为查询语言来查找数据,而采用key-value形式进行查找,提供了更高的查询效率及吞吐,并且能够更加方便地进行扩展,存储海量数据,在数千个节点上进行分区,自动进行数据的复制和备份。在分布式系统中,消息作为应用间通信的一种方式,得到了十分广泛的应用。消息可以被保存在队列中,直到被接收者取出,由于消息发送者不需要同步等待消息接收者的响应,消息的异步接收降低了系统集成的耦合度,提升了分布式系统协作的效率,使得系统能够更快地响应用户,提供更高的吞吐。当系统处于峰值压力时,分布式消息队列还能够作为缓冲,削峰填谷,缓解集群的压力,避免整个系统被压垮。垂直化的搜索引擎在分布式系统中是一个非常重要的角色,它既能够满足用户对于全文检索、模糊匹配的需求,解决数据库like查询效率低下的问题,又能够解决分布式环境下,由于采用分库分表,或者使用NoSQL数据库,导致无法进行多表关联或者进行复杂查询的问题。